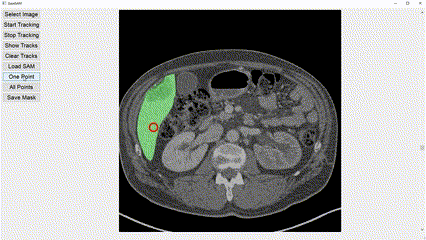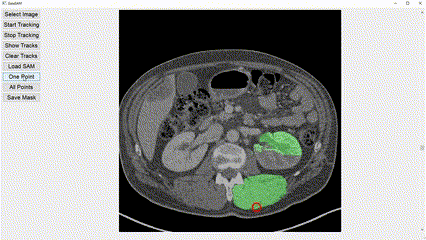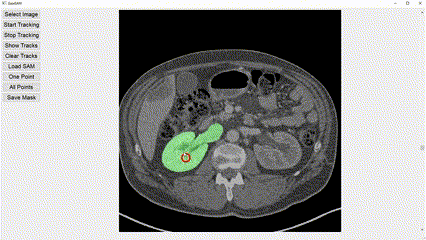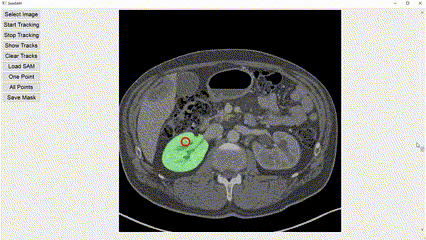
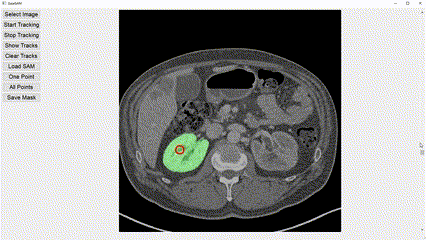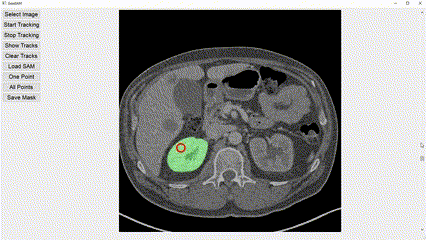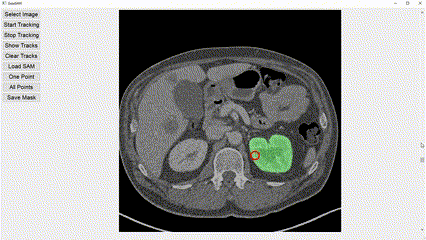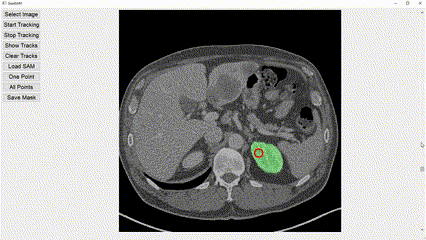
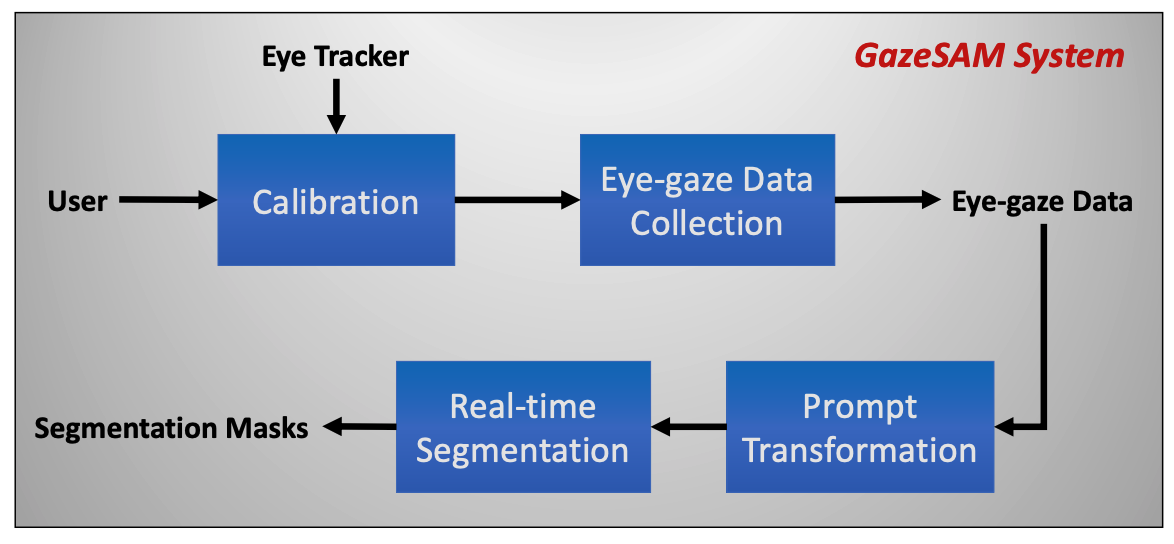
Interactive image segmentation aims to assist users in efficiently generating high-quality data annotations through user-friendly interactions such as clicking, scribbling, and bounding boxes. However, mouse-based interaction methods can induce user fatigue during large-scale dataset annotation and are not entirely suitable for some domains, such as radiology. This study introduces eye gaze as a novel interactive prompt for image segmentation, different than previous model-based applications. Specifically, leveraging the real-time interactive prompting feature of the recently proposed Segment Anything Model (SAM), we present the GazeSAM system to enable users to collect target segmentation masks by simply looking at the region of interest. GazeSAM tracks users' eye gaze and utilizes it as the input prompt for SAM, generating target segmentation masks in real time. To our best knowledge, GazeSAM is the first work to combine eye gaze and SAM for interactive image segmentation. Experimental results demonstrate that GazeSAM can improve nearly 50% efficiency in 2D natural image and 3D medical image segmentation tasks.
Our analysis reveals the eye gaze-based interaction is more efficient than mouse-based interaction.

(a) It is more natural and intuitive because eye gaze-based interaction aligns with how humans naturally perceive objects by simply looking at them.
(b) It can reduce user fatigue significantly. Using a mouse to annotate large-scale datasets will lead to a tedious click job.
(c) eye gaze enables faster and more efficient interactions. Users can simply glance at the object they want to segment without the need for mouse clicking or drawing
(d) Using eye gaze as interaction input can generate multiple prompt input points in less than one second, which can input more information into the automated model in a short time, increasing the accuracy of the generated segmentation masks.
Experimental results demonstrate that GazeSAM can improve nearly 50% efficiency in 2D natural image and 3D medical image segmentation tasks.


@article{wang2023gazesam,
title={GazeSAM: What You See is What You Segment},
author={Wang, Bin and Aboah, Armstrong and Zhang, Zheyuan and Bagci, Ulas},
journal={arXiv preprint arXiv:2304.13844},
year={2023}
}