Virtual Cloth Try-on based on Segment Anything and Conditional Generative Models
Course Project of CS496 Deep Generative Models
- Mingfu Liang 1
- Bin Wang 1
- 1 Northwestern University
- mingfuliang2020@u.northwestern.edu
- Course Advisor: Bryan Pardo
Virtual Try-on gives us a flexible way to try the cloth we desired without going into the shop onsite. However, existing try-on application require the user to passively choose from a pre-defined set of clothes, which is time consuming, especially when we already had a desired clothes. Thus in this project we want to enable an interactive personalized system for virtual try-on, i.e., let the user actively indicate their intent by providing either text guidance, e.g., a description of the cloth of interested, or image guidance, i.e., the image of the cloth they desired.
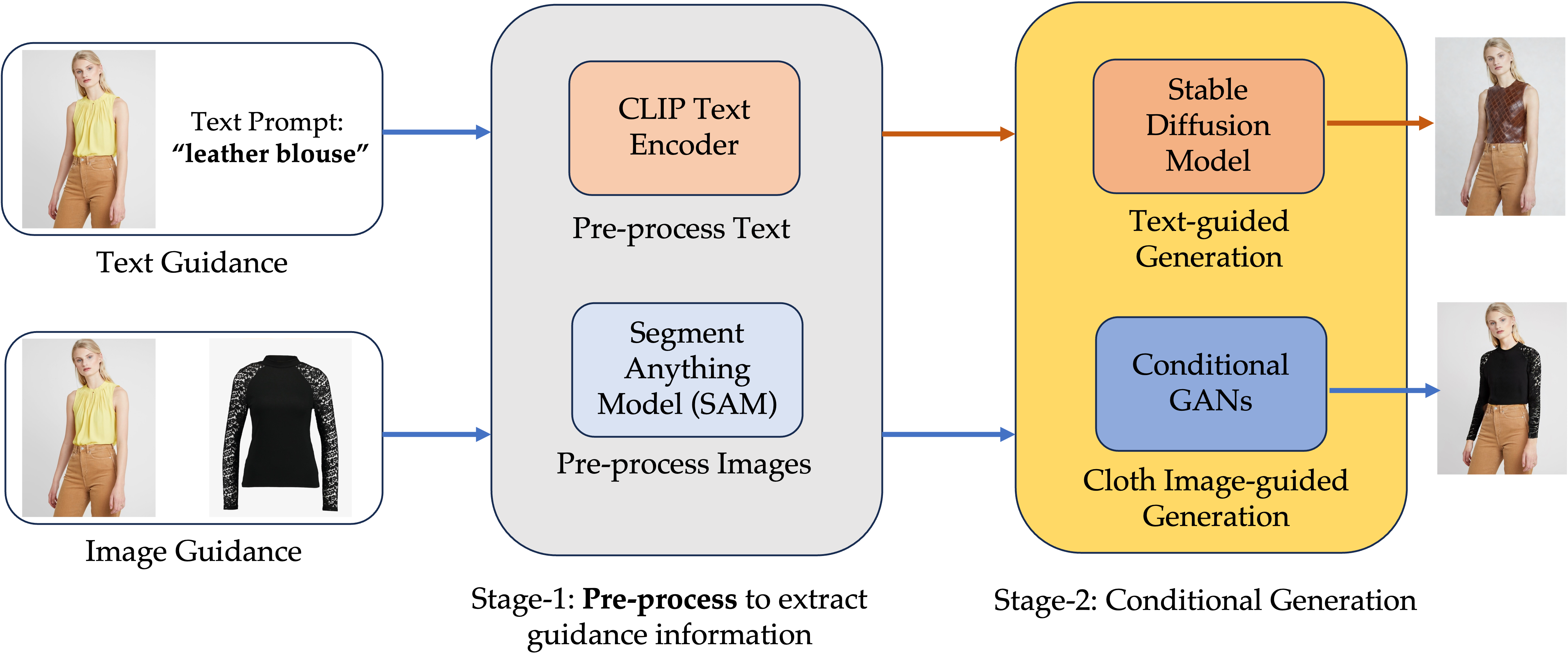
To do so, we propose the following framework. The user will first upload a source image accompany with a text prompt or a cloth image prompt. In the Stage-1, we will pre-process both the text and images to extract essential guidance information, where we use CLIP text encoder to encode the text and for the images, we use the segment anything model to extract the primitives of the images, for example the segment mask of the cloth and the boundary map of the human body. Then in the Stage-2, we will correspondingly perform either text-guided generation or cloth image-guided generation.
Extend ControlNet to Finetune the Stable Diffusion for Text-guided VITON
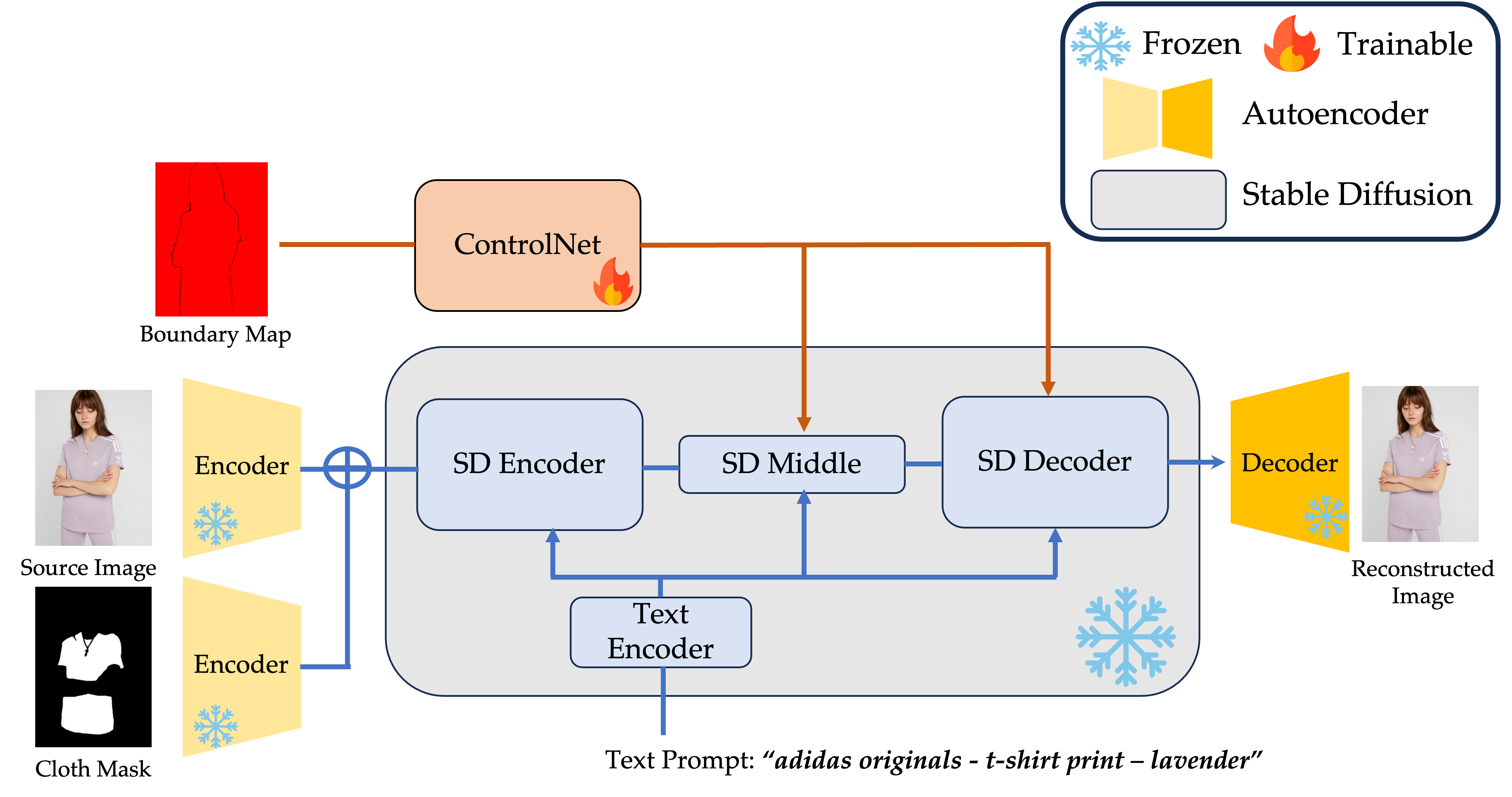
Now I introduce how we extend stable diffusion model for Virtual Try-on by the controlnet. We freeze the pretrained autoencoder and the stable diffusion model, which is released by Stability AI. As mentioned before, we have a source image and then the SAM will preprocess it to return a cloth mask and a boundary map correspondingly. The controlnet is a copy of the SD encoder which will input the boundary map to constraint on the generation. The text prompt will input to the text encoder and condition on the whole generation process in stable diffusion.
Qualitative Results of Text-guided VITON

Explored Image-guided VITON
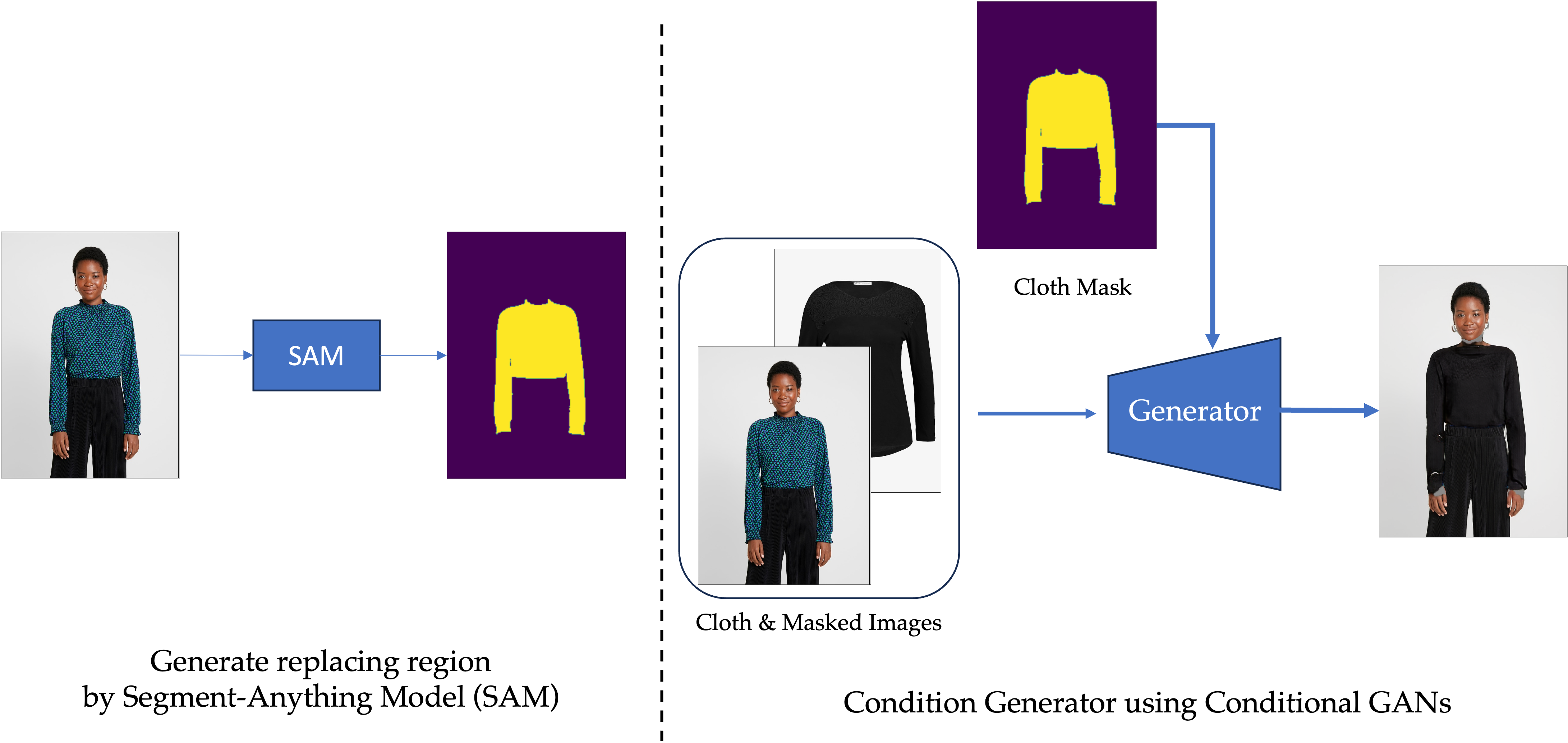
Originally we have text prompt here, and we input the edge map into the controlnet to control the image generation. At first, we think it should be natural if we change the edge map into the cloth item image and make the text prompt as empty, then it will guide the model to generate a cloth on the human body. After more than a week trial and error, we find that it is hard to enforce pixel-wise consistency by only manipulating the latent space during generation for image-guided VITON, because here we first pass the image into the encoder and doing alignment between cloth and source image based on the encoding feature. It is not pixel-wise and we can not directly align the cloth with the human body in image space. Therefore, we instead consider the conditional GAN model and directly do the generation starting from the image space Here we first use segmentanything model to generate a region mask where we want to generate a new cloth on it, then we take the mask as the conditioning image of the generator and conduct the image generator. This is better because the image and cloth is not passed into encoder and they can directly do the alignment in the image space, and also there will be pixel-wise supervision to make the final prediction look more natural.
An Interactive Demo for Proof-of-Concept
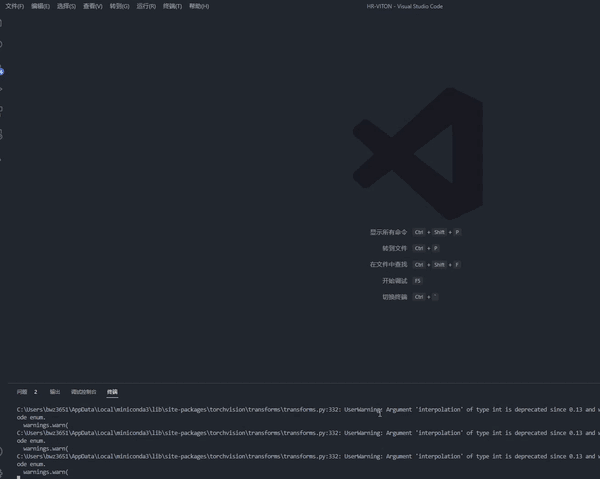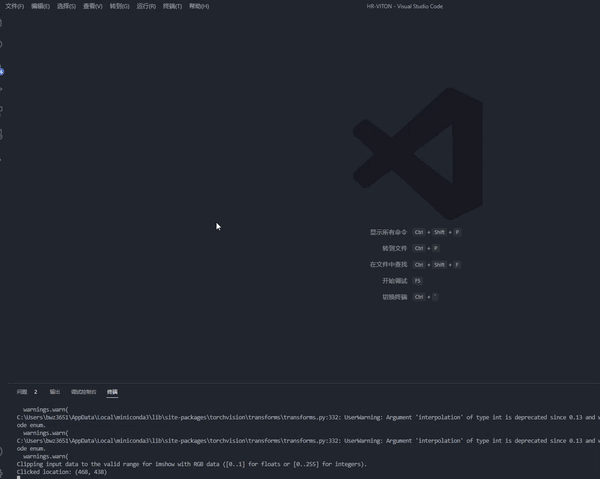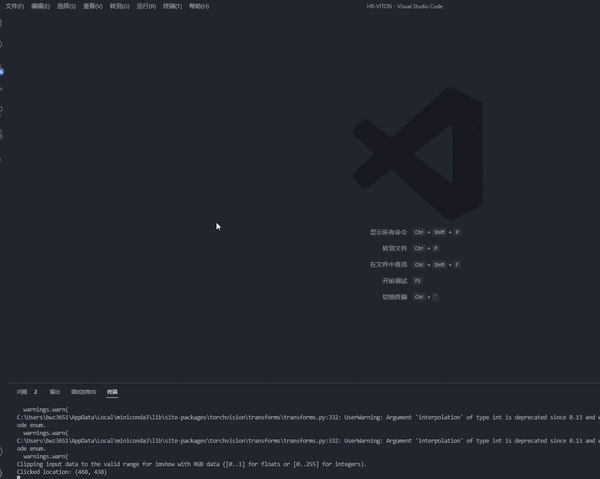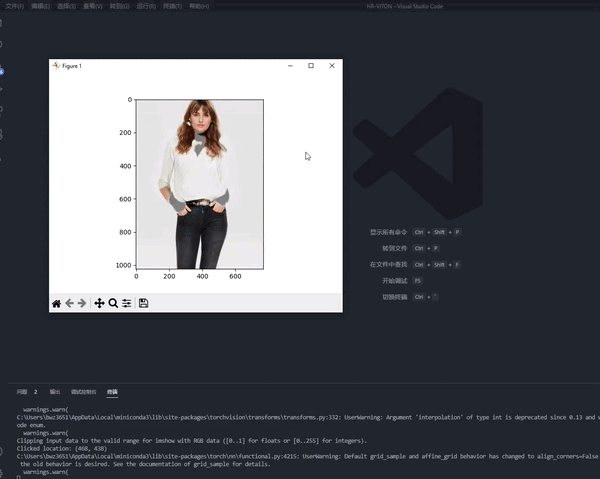
Qualitative Results of Image-guided VITON
